1 问题及数据集
1.1 问题
给定较长一段话的context和一个较短的问题,以及一些candidate answers,训练出可以准确预测正确答案的模型,本模型主要针对命名实体和常用名词这两种词性的单词进行填空。
1.2数据集
(1)CNN&Daily Mail
(2)CBT
2 已有方法
(1)Attentive and Impatient Readers
(2)Attentive
(3)Chen et al. 2016
(4)MemNNs
(5)Pointer Networks
(6)Dynamic Entity Representation
3 本文提出的方法
ASReader模型使用注意力机制计算每个单词的注意力权重之和,从而从上下文中选择答案,而不是像在之前的模型一样,使用文档与问题的相似度或提取特征构建特征工程等方式来定位答案。
4 具体内容
4.1 网络结构
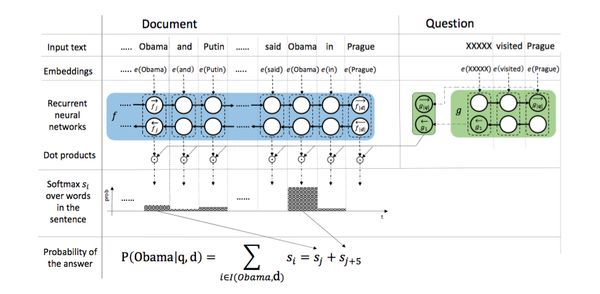
4.2具体过程
step1:通过一层Embedding层将document和query中的word分别映射成向量。
step2:用一个单层双向GRU来encode document,得到context representation,每个time step的拼接来表示该词
step3:用一个单层双向GRU来encode query,用两个方向的last state拼接来表示query。
step4:每个word vector与query vector作点积后归一化的结果作为attention weights,就query与document中的每个词之前的相关性度量。
step5:最后做一次相同词概率的合并,得到每个词的概率,最大概率的那个词即为answer。为节约计算时间,可以只选择candidate answer里的词来计算概率。
4.3 评估方法
average ensemble by top 20%:更改初始化参数,训练多个模型,然后取在验证集上效果最好的前20%个模型做bagging.
average ensemble:取前效果排名前70%的model做bagging
greedy ensemble:根据效果排序从效果最好的模型开始bagging,如果bagging后的模型在验证集上效果更好就加入,一直持续到最后。
5.实验结果
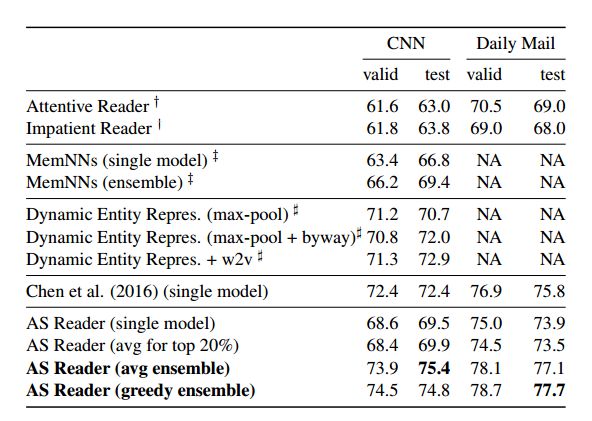
5.1.CNN/Daily Mail
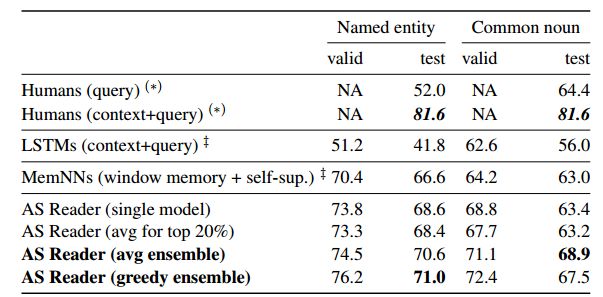
5.2.CBT
6 小结
(1)利用点积来计算注意力权重,简化了模型,但是能达到同样或者更好的效果。
(2)利用注意力权重之和来选择答案,而不是像以前的工作那样通过权重提取特征从而预测答案,但该模型更倾向于选择重复次数较多的单词作为答案。